Artykuł ten otwiera serię artykułów o bibliotece Pandas. Czym jest Pandas? Jest to swego rodzaju swiss army knife w zakresie analizy danych z wykorzystaniem Pythona. Biblioteka ta oferuje wszechstronny zakres funkcjonalności od wczytania danych z różnych rodzajów plików do pamięci poprzez przetwarzanie danych po ich wizualizację. W niniejszym artykule omówię jak zacząć swoją przygodę z tą biblioteką czyli jak wczytać dane do analizy i wykonać na tych danych kilka elementarnych operacji jak np. wyświetlenie kilku ich wierszy.
Jako przykładowe dane posłużą w tym artykule dane o klockach Lego pobrane ze strony rebrickable.com (plik sets.csv.gz). Znajdziecie tam więcej zbiorów danych z informacjami o klockach Lego.
Najprostszy sposób wczytania danych z pliku CSV
W pierwszym kroku wczytujemy bibliotekę:
In [1]:
import pandas as pd
W praktyce bibliotekę Pandas zazwyczaj używamy z wykorzystaniem aliasu pd.
W ogólnym przypadku do nadania aliasu importowanemu elementowi stosujemy konstrukcję:
import nazwa_biblioteki as alias_biblioteki
Dzięki temu możemy w kodzie wykorzystywać elementy biblioteki bez potrzeby poprzedzania ich jej pełną nazwą.
Wykorzystanie aliasu możemy zobaczyć na przykładzie poniższego polecenia, które pozwala na wczytanie danych z pliku CSV – polecenie pd.read_csv() (gdybyśmy nie zastowali przy imporcie frazy „as pd” musielibyśmy zamiast pd.read_csv() użyć panadas.read_csv())
In [2]:
nazwa_pliku_csv = 'sets.csv'
df = pd.read_csv(nazwa_pliku_csv)
Dane z pliku sets.csv zostały wczytywane do obiektu DataFrame reprezentoweanego przez zmienną df .
O obiekcie DataFrame, do kórego mamy dostęp poprzez naszą zmienną df, można myśleć jak o arkuszu Excela (wiersze, kolumny, czy w końcu pojedyńcze komórki), przy czym nie ma on reprezentacji graficznej w postaci jakiegoś okna jak ma to miejsce w Excelu. Można za to operować na tym obiekcie pisząc kod wykorzystujący wbudowane w DataFrame metody.
Elementarne operacje na DataFrame
Kilka pierwszych wierszy danych można wyświetlić poleceniem:
In [3]:
df.head()
Out[3]:
| set_num | name | year | theme_id | num_parts | |
|---|---|---|---|---|---|
| 0 | 001-1 | Gears | 1965 | 1 | 43 |
| 1 | 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 2 | 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 3 | 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 4 | 0013-1 | Space Mini-Figures | 1979 | 143 | 12 |
W podobny sposób można również wyświetlić kilka ostatnich wierszy za pomocą polecenia:
In [4]:
df.tail()
Out[4]:
| set_num | name | year | theme_id | num_parts | |
|---|---|---|---|---|---|
| 16496 | XWING-1 | Mini X-Wing Fighter | 2019 | 158 | 60 |
| 16497 | XWING-2 | X-Wing Trench Run | 2019 | 158 | 52 |
| 16498 | YODACHRON-1 | Yoda Chronicles Promotional Set | 2013 | 158 | 413 |
| 16499 | YTERRIER-1 | Yorkshire Terrier | 2018 | 598 | 0 |
| 16500 | ZX8000-1 | ZX 8000 LEGO Sneaker | 2020 | 501 | 0 |
Metody head() oraz tail() domyślnie wyświetlają po 5 wierszy odpowiednio początkowych i końcowych. Można jednak określić liczbę wierszy, która ma zostać wyświetlona jako parametr wywołania tych metod, przykładowo aby wyświetlnić pierwsze 10 wierszy wywołujemy:
In [5]:
df.head(10)
Out[5]:
| set_num | name | year | theme_id | num_parts | |
|---|---|---|---|---|---|
| 0 | 001-1 | Gears | 1965 | 1 | 43 |
| 1 | 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 2 | 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 3 | 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 4 | 0013-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 5 | 0014-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 6 | 0015-1 | Space Mini-Figures | 1979 | 143 | 18 |
| 7 | 0016-1 | Castle Mini Figures | 1978 | 186 | 15 |
| 8 | 002-1 | 4.5V Samsonite Gears Motor Set | 1965 | 1 | 3 |
| 9 | 003-1 | Master Mechanic Set | 1966 | 366 | 403 |
Informację o rozmiarze danych możemy uzyskać poprzez atrybut shape DataFrame:
In [6]:
df.shape
Out[6]:
(16501, 5)
Jak widzimy powyżej DataFrame df zawiera 16501 wierszy oraz 5 kolumn.
Kolejną metodą DataFrame, którą użyjemy jest info()
In [7]:
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 16501 entries, 0 to 16500 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 set_num 16501 non-null object 1 name 16501 non-null object 2 year 16501 non-null int64 3 theme_id 16501 non-null int64 4 num_parts 16501 non-null int64 dtypes: int64(3), object(2) memory usage: 644.7+ KB
Metoda ta zwraca podstawowe informacje o zawartości DataFrame. Dla każdej kolumny wyświetla:
- nazwę,
- liczby niepustych wartości w niej zawartych,
- typ przechowywanych danych.
Ponadto metoda ta wyświetla informacje:
- liczbę wierszy oraz zakres indeksu,
- rozmiar pamięci zajmowany przez DataFrame,
- pełną nazwę typu zmiennej df (czyli 'pandas.core.frame.DataFrame’).
Podstawowe informacje statystyczne o kolumnach takie jak:
- liczba wartości
- średnia
- odchylenie standardowe
- wartość minimalna
- wartość maksymalna
- percentyle 25%, 50% (czyli mediana), 75%
można uzyskać za pomocą metody describe()
In [8]:
df.describe()
Out[8]:
| year | theme_id | num_parts | |
|---|---|---|---|
| count | 16501.000000 | 16501.000000 | 16501.000000 |
| mean | 2005.143203 | 391.844252 | 163.369796 |
| std | 13.977152 | 200.821368 | 377.246526 |
| min | 1949.000000 | 1.000000 | 0.000000 |
| 25% | 1999.000000 | 227.000000 | 8.000000 |
| 50% | 2009.000000 | 452.000000 | 42.000000 |
| 75% | 2016.000000 | 524.000000 | 159.000000 |
| max | 2021.000000 | 712.000000 | 9987.000000 |
Podstawowe parametry funkcji read_csv()
We wcześniejszym przykładzie wczytane zostały dane z pliku za pomocą pd.read_csv(), w której wywołaniu podany został jeden parametr – nazwa pliku. Można powiedzieć, że jest to najprostszy sposób wykorzystania tej funkcji. pd.read_csv() ma bardzo bogaty zestaw parametrów pozwalających na dostosowanie jej działania do naszych potrzeb. Umożliwiają one parametryzację czytania danych odpowiednio do specyfiki pliku z danymi i oczekiwanej przez nas struktury DataFrame po ich wczytaniu. Pełna dokumentacja funkcji dostępna jest na stronie pandas.read_csv Omówię teraz najczęściej przydatne parametry pd.read_csv().
Pierwszym parametrem, o którym warto powiedzieć jest parametr pozwalający na określenie separatora rozdzielającego dane w kolejnych kolumnach. De facto mamy tutaj do dyspozycji dwa parametry:
- sep,
- delimiter (alias parametru sep).
Domyślną wartością parametru, czyli w sytuacji gdy go jawnie nie podamy w wywołaniu funkcji jest przecinek. Właśnie z wartością domyślną parametru sep wczytane zostały dane we wcześniejszym przykładzie.
Spróbujmy teraz ponownie wczytać te same dane ale ze średnikiem jako separatorem.
In [9]:
df = pd.read_csv(nazwa_pliku_csv, sep=';') df.head()
Out[9]:
| set_num,name,year,theme_id,num_parts | |
|---|---|
| 0 | 001-1,Gears,1965,1,43 |
| 1 | 0011-2,Town Mini-Figures,1978,84,12 |
| 2 | 0011-3,Castle 2 for 1 Bonus Offer,1987,199,0 |
| 3 | 0012-1,Space Mini-Figures,1979,143,12 |
| 4 | 0013-1,Space Mini-Figures,1979,143,12 |
In [10]:
df.shape
Out[10]:
(16501, 1)
Jak widzimy powyżej dane zostały wczytane do DataFrame. Podobnie jak wcześniej obiekt ten zawiera 16501 wierszy ale tylko jedną kolumnę. Ze względu na to, że średnik nie jest prawdiłowym separatorem danych dla naszego pliku, dane w pliku zostały potraktowane jako jedna kolumna, która została nazwana „zlepkiem” rzeczywistych nazw kolumn przedzielonych przecinkami „set_num,name,year,theme_id,num_parts„. czyli ciągiem znaków z wiersza nagłówkowego.
Sterowanie nagłówkiem danych – modyfikowanie nazw kolumn
W kolejnym przykładzie podamy prawidłowy separator danych oraz dodatkowo wprowadzimy parametr header pozwalający na sterowanie jak ma być traktowany nagłówek. W poniższym przykładzie header=None co oznacza, że dane w pliku nie mają nagłówka.
In [11]:
df = pd.read_csv(nazwa_pliku_csv, sep=',', header=None) df.head()
Out[11]:
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | set_num | name | year | theme_id | num_parts |
| 1 | 001-1 | Gears | 1965 | 1 | 43 |
| 2 | 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 3 | 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 4 | 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
In [12]:
df.shape
Out[12]:
(16502, 5)
Jak widzimy dane zostały wczytane. Możemy też zauważyć, że liczba wierszy we wczytanym DataFrame jest większa o 1 w stosunku do poprzedniego przykładu. Wiersz nagłówka został bowiem potraktowany jak dane. Z tego wzgledu poszczególne kolumny nie mają nazw opisowych, zostały za to ponumerowane od 0 do 4. Za to w pierwszym wierszu widzimy właściwe nazwy kolumn. Wynika, to oczywiście z tego, że dane w pliku mają nagłówek i w takiej sytuacji nie powinniśmy używać header=None. Skorygujmy to zatem i określmy, że pierwszy wiersz w pliku zawiera nagłówek.
In [13]:
df = pd.read_csv(nazwa_pliku_csv, sep=',', header=0) df.head()
Out[13]:
| set_num | name | year | theme_id | num_parts | |
|---|---|---|---|---|---|
| 0 | 001-1 | Gears | 1965 | 1 | 43 |
| 1 | 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 2 | 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 3 | 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 4 | 0013-1 | Space Mini-Figures | 1979 | 143 | 12 |
In [14]:
df.shape
Out[14]:
(16501, 5)
Jak widzimy tym razem dane zostały wczytane zgodnie z naszymi oczekiwaniami, czyli z nazwami kolumn zawartymi w pliku. Liczba wierszy również wróciła do poprawnej wartości.
Taki sam efekt możemy uzyskać poprzez określenie wartości parametru header=’infer’. Warto zaznaczyć, że ’infer’ jest wartością domyślną parametru header.
In [15]:
df = pd.read_csv(nazwa_pliku_csv, sep=',', header='infer') df.head()
Out[15]:
| set_num | name | year | theme_id | num_parts | |
|---|---|---|---|---|---|
| 0 | 001-1 | Gears | 1965 | 1 | 43 |
| 1 | 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 2 | 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 3 | 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 4 | 0013-1 | Space Mini-Figures | 1979 | 143 | 12 |
Potrafimy już sterować nagłówkiem danych. W tym miejscu może się pojawić pytanie: Jak mogę dostosować nazwy kolumn do swoich potrzeb?
Chcąc nadać własne nazwy kolumnom podczas wczytywania danych z pliku należy podać dwa parametry:
- parametr header=0,
- oraz podać listę nazw w parametrze names.
Dzięki temu nazwy z pierwszego wiersza pliku zostaną zastąpione nazwami z listy names
In [16]:
df = pd.read_csv(nazwa_pliku_csv, delimiter=',', header=0, names=['Nr zestawu', 'Nazwa', 'Rok', 'Id tematu', 'Liczba części']) df.head()
Out[16]:
| Nr zestawu | Nazwa | Rok | Id tematu | Liczba części | |
|---|---|---|---|---|---|
| 0 | 001-1 | Gears | 1965 | 1 | 43 |
| 1 | 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 2 | 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 3 | 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 4 | 0013-1 | Space Mini-Figures | 1979 | 143 | 12 |
In [17]:
df.shape
Out[17]:
(16501, 5)
Warto tutaj zwrócić uwagę, że nazwy kolumn można też łatwo zmienić po wczytaniu danych za pomocą atrybutu DataFrame.
Wczytajmy ponownie dane podając tylko nawę pliku.
In [18]:
df = pd.read_csv(nazwa_pliku_csv) df.head()
Out[18]:
| set_num | name | year | theme_id | num_parts | |
|---|---|---|---|---|---|
| 0 | 001-1 | Gears | 1965 | 1 | 43 |
| 1 | 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 2 | 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 3 | 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 4 | 0013-1 | Space Mini-Figures | 1979 | 143 | 12 |
In [19]:
df.shape
Out[19]:
(16501, 5)
Teraz możemy zastąpić wczytane nazwy kolumn polskimi nazwami przypisując je do atrybutu df.columns
In [20]:
df.columns = ['Nr zestawu', 'Nazwa', 'Rok', 'Id tematu', 'Liczba części'] df.head()
Out[20]:
| Nr zestawu | Nazwa | Rok | Id tematu | Liczba części | |
|---|---|---|---|---|---|
| 0 | 001-1 | Gears | 1965 | 1 | 43 |
| 1 | 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 2 | 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 3 | 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 4 | 0013-1 | Space Mini-Figures | 1979 | 143 | 12 |
Jak widać uzyskaliśmy w ten sposób taki sam efekt jak wcześniej poprzez określenie parametru names w funkcji pd.read_csv().
Sterowanie indeksem danych
Kolejny parametr, który omówimy to index_col. Pozwala on wskazać kolumnę, która będzie pełnić rolę indeksu. Indeks można traktować jako identyfikator czy nazwę wiersza. Podobnie jak nazwa kolumny pozwala na jej identyfikację i odwoływanie się do niej. W poniższym przykładzie pierwsza kolumna zostanie użyta jako indeks.
In [21]:
df = pd.read_csv(nazwa_pliku_csv, delimiter=',', header=0, names=['Nr zestawu', 'Nazwa', 'Rok', 'Id tematu', 'Liczba części'], index_col=0) df.head()
Out[21]:
| Nazwa | Rok | Id tematu | Liczba części | |
|---|---|---|---|---|
| Nr zestawu | ||||
| 001-1 | Gears | 1965 | 1 | 43 |
| 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 0013-1 | Space Mini-Figures | 1979 | 143 | 12 |
In [22]:
df.shape
Out[22]:
(16501, 4)
Jak widzimy początkowe 5 wierszy naszych danych wygląda teraz inaczej niż wcześniej. Po lewej stronie nie ma już numerów wierszy (0,1, 2, …). Zostały one zastąpione wartościami kolumny „Nr zestawu”, która została określona w parametrach jako kolumna indeksu poprzez ustawienie index_col=0.
Co więcej zmienił się rozmiar naszego DataFrame. Aktualnie mamy 16501 wierszy i 4 kolumny. We wcześniejszym przykładzie mieliśmy tyle samo wierszy ale 5 kolumn. Co się stało z jedna kolumną? Tak jak już wcześniej powiedziałem została ona użyta jako indeks i tym samym nie wystepuje już jako kolumna, a indeks. Do indeksu mamy dostęp poprzez atrybutu index DataFrame
In [23]:
df.index
Out[23]:
Index(['001-1', '0011-2', '0011-3', '0012-1', '0013-1', '0014-1', '0015-1',
'0016-1', '002-1', '003-1',
...
'WIESBADEN-1', 'WILLIAM-1', 'WISHINGWELL-1', 'WWGP-1', 'XMASTREE-1',
'XWING-1', 'XWING-2', 'YODACHRON-1', 'YTERRIER-1', 'ZX8000-1'],
dtype='object', name='Nr zestawu', length=16501)
Podobnie jak w przypadku zmian nazw kolumn, indeks możemy również ustawić po wczytaniu danych. Wczytajmy ponownie dane podając jako parametr pd.read_csv() jedynie nazwę pliku.
In [24]:
df = pd.read_csv(nazwa_pliku_csv) df.head()
Out[24]:
| set_num | name | year | theme_id | num_parts | |
|---|---|---|---|---|---|
| 0 | 001-1 | Gears | 1965 | 1 | 43 |
| 1 | 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 2 | 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 3 | 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 4 | 0013-1 | Space Mini-Figures | 1979 | 143 | 12 |
Ustawmy teraz jako indeks kolumnę ’set_num’ poleceniem:
In [25]:
df.set_index('set_num', inplace=True)
df.head()
Out[25]:
| name | year | theme_id | num_parts | |
|---|---|---|---|---|
| set_num | ||||
| 001-1 | Gears | 1965 | 1 | 43 |
| 0011-2 | Town Mini-Figures | 1978 | 84 | 12 |
| 0011-3 | Castle 2 for 1 Bonus Offer | 1987 | 199 | 0 |
| 0012-1 | Space Mini-Figures | 1979 | 143 | 12 |
| 0013-1 | Space Mini-Figures | 1979 | 143 | 12 |
Jak widzimy uzyskaliśmy taki sam efekt jak wcześniej, gdy określiliśmy w funkcji read_csv(), że pierwsza kolumna w pliku to kolumna indeksu.
Uwaga: Jeżeli chcemy aby zmiana indeksu została wprowadzona do DataFrame, dla którego wywołujemy metodę set_index() musimy przekazać do niej parameter inplace = True. Jeżeli tego nie zrobimy to ten DataFrame nie zostanie zmieniony, a metoda zwróci wtedy nowy DataFrame z ustawionym indeksem. Warto o tym pamiętać, bo może nam się wydawać że metoda set_index() nie zadziała.
Dostęp do danych
Do danych w DataFrame możemy odwoływać się jak do dwuwymiarowej listy za pomocą dwóch atrybutów DataFrame loc i iloc.
Atrybuty:
- iloc pozawala na określenie komórek poprzez podanie numerów wierszy i komórek.
- loc pozwala na określenie komórek poprzez nazwy wiersza (wartości indeksu) i nazwy kolumny.
Przykładowo za pomocą iloc możemy wybrać pierwszy wiersz DataFrame df:
In [26]:
df.iloc[0]
Out[26]:
name Gears year 1965 theme_id 1 num_parts 43 Name: 001-1, dtype: object
In [27]:
df.iloc[:1]
Out[27]:
| name | year | theme_id | num_parts | |
|---|---|---|---|---|
| set_num | ||||
| 001-1 | Gears | 1965 | 1 | 43 |
UWAGA: wiersze i kolumny numerowane są od 0.
UWAGA: Notacja „[:10]” oznacza, że wybrane mają być pozycje listy z zakresu 0 <= x < 10. W powyższym przykładzie mamy „[:1]” czyli zwrócony zostanie tylko pierwszy wiersz DataFrame.
Wcześniej wspomniałem, że DataFrame możemy postrzegać jako dwywymiarową listę. W kolejnym przykładzie wybierzemy wartości pierwszej kolumny dla wszystkich wierszy. W tym celu wykonamy polecenie
In [28]:
df.iloc[:,0]
Out[28]:
set_num
001-1 Gears
0011-2 Town Mini-Figures
0011-3 Castle 2 for 1 Bonus Offer
0012-1 Space Mini-Figures
0013-1 Space Mini-Figures
...
XWING-1 Mini X-Wing Fighter
XWING-2 X-Wing Trench Run
YODACHRON-1 Yoda Chronicles Promotional Set
YTERRIER-1 Yorkshire Terrier
ZX8000-1 ZX 8000 LEGO Sneaker
Name: name, Length: 16501, dtype: object
W przykładzie tym wprowadzony został drugi wymiar po przecinku (kolumna numer 0). W ogólność możemy wybierać dane podając:
[nr wiersza początkowego:nr wiersza końcowy : krok dla wierszy, nr kolumny początkowej:nr kolumny końcowej:krok dla kolumn]
- nr wiersza początkowego <= wiersz < nr wiersza końcowego
- nr kolumny początkowej <= kolumna < nr kolumny końcowej
- krok – liczba całkowita określająca krok z jakim przechodzimy od wartości początkowej do końcowej, domyślnie 1. W celu wybrania co drugiego wiersza należy określić wartość krok dla wierszy = 2
Przejdźmy teraz do drugiej metody wyboru danych z DataFrame, tj. atrybutu loc. W pierwszym przykładzie wybierzmy pierwszy wiersz. W tym celu podamy w atrybucie loc wartość indeksu dla pierwszego wiersza czyli „001-1”:
In [29]:
df.loc['001-1']
Out[29]:
name Gears year 1965 theme_id 1 num_parts 43 Name: 001-1, dtype: object
Teraz wybierzmy wartości z kolumny ’theme_id’ dla wszystkich wierszy:
In [30]:
df.loc[:,'theme_id']
Out[30]:
set_num
001-1 1
0011-2 84
0011-3 199
0012-1 143
0013-1 143
...
XWING-1 158
XWING-2 158
YODACHRON-1 158
YTERRIER-1 598
ZX8000-1 501
Name: theme_id, Length: 16501, dtype: int64
Ogólny schemat specyfikowania parameterów wybory danych jest taki sam jak dla atrybutu iloc, z tą różnicą, że zamiast numerów podajemy nazwy z indeksu dla wierszy oraz nazwy kolumn. W szczególności możemy określić krok, na przykład aby wybrać co drugi wiersz w powyższym przykładzie wykonujemy polecenie:
In [31]:
df.loc[::2,'theme_id']
Out[31]:
set_num
001-1 1
0011-3 199
0013-1 143
0015-1 143
002-1 1
...
WILLIAM-1 535
WWGP-1 476
XWING-1 158
YODACHRON-1 158
ZX8000-1 501
Name: theme_id, Length: 8251, dtype: int64
Filtrowanie danych
Kolejną operacją na danych, którą omówię jest filtrowanie danych w DataFrame. Dane można filtrować określając filtr w sposób podany poniżej. Polecenie to zwróci informacje o zestawach klocków lego, które były produktowane w 2020 roku.
In [32]:
df[ df['year'] == 2020]
Out[32]:
| name | year | theme_id | num_parts | |
|---|---|---|---|---|
| set_num | ||||
| 0744023726-1 | Disney Princess: Enchanted Treasury | 2020 | 497 | 4 |
| 0744023734-1 | LEGO Minifigure: A Visual History New Edition | 2020 | 497 | 5 |
| 0744024471-1 | 100 Ways to Rebuild the World | 2020 | 497 | 0 |
| 10270-1 | Bookshop | 2020 | 155 | 2504 |
| 10271-1 | Fiat 500 | 2020 | 673 | 960 |
| … | … | … | … | … |
| TEDDYBEAR-1 | Teddy Bear | 2020 | 232 | 67 |
| TOUCAN2020-1 | Toucan | 2020 | 621 | 22 |
| TOWEL-1 | Cars Microfiber Towel | 2020 | 501 | 0 |
| TRADINGCARD-3 | Create the World Trading Cards: Living Amazingly | 2020 | 501 | 139 |
| ZX8000-1 | ZX 8000 LEGO Sneaker | 2020 | 501 | 0 |
826 rows × 4 columns
Warunek filtru możemy również podać jako zmienną:
In [33]:
filtr = df['year'] == 2020 df[filtr]
Out[33]:
| name | year | theme_id | num_parts | |
|---|---|---|---|---|
| set_num | ||||
| 0744023726-1 | Disney Princess: Enchanted Treasury | 2020 | 497 | 4 |
| 0744023734-1 | LEGO Minifigure: A Visual History New Edition | 2020 | 497 | 5 |
| 0744024471-1 | 100 Ways to Rebuild the World | 2020 | 497 | 0 |
| 10270-1 | Bookshop | 2020 | 155 | 2504 |
| 10271-1 | Fiat 500 | 2020 | 673 | 960 |
| … | … | … | … | … |
| TEDDYBEAR-1 | Teddy Bear | 2020 | 232 | 67 |
| TOUCAN2020-1 | Toucan | 2020 | 621 | 22 |
| TOWEL-1 | Cars Microfiber Towel | 2020 | 501 | 0 |
| TRADINGCARD-3 | Create the World Trading Cards: Living Amazingly | 2020 | 501 | 139 |
| ZX8000-1 | ZX 8000 LEGO Sneaker | 2020 | 501 | 0 |
826 rows × 4 columns
Za pomocą metod head() praz tail() możemy się dowiedzieć jakie wartości ma nasz filtr
In [34]:
filtr.head()
Out[34]:
set_num 001-1 False 0011-2 False 0011-3 False 0012-1 False 0013-1 False Name: year, dtype: bool
In [35]:
filtr.tail()
Out[35]:
set_num XWING-1 False XWING-2 False YODACHRON-1 False YTERRIER-1 False ZX8000-1 True Name: year, dtype: bool
Jak widzimy zmienna filtr zawiera dla każdego wiersza wartości True lub False w zależności czy wartość kolumny 'year’ dla tego wiersza to 2020 czy nie. Biorąc pod uwagę te wartości w wyniku filtrowania wiersz z DataFrame jest zwracany (gdy wartość filtru dla wiersza jest równaTrue) bądź nie (w przeciwnym wypadku).
Grupowanie danych
Następną operacją, z którą często mamy doczynienia w praktyce jest grupowanie, które można wykonać dla DataFrame za pomocą metody groupby(). Przykładowo w celu określenia ile zestawów klocków było produkowanych w poszczególnych latach możemy wykonać polecenie:
In [36]:
df_year = df.groupby('year')['name'].count()
df_year.head()
Out[36]:
year 1949 5 1950 6 1953 4 1954 14 1955 28 Name: name, dtype: int64
W poleceniu tym dokonujemy grupowania i zliczenia elementów w grupie metodą count(). Oprócz zliczania elementów możemy np. sumować wartość w grupie sum(), określać dla grupy wartości minimalną min(), maksymalną max(), średnią mean(), itp.
W tym miejscu warto napisać jeszcze o jednym poleceniu nlargest(), które pozwoli nam na uzyskaniu informacji, w których latach powstało najwięcej zestawów.
In [37]:
df_year.nlargest(5)
Out[37]:
year 2019 881 2017 834 2018 832 2020 826 2016 779 Name: name, dtype: int64
Wizualizacja danych
Jedną z niewątpliwie bardzo użytecznych rzeczy w analizie danych jest ich wizualizacja. Z tego względu teraz czas na dwa słowa o tym jak wizualizować dane za pomocą Pandas. Tak, tak, tak jak wspomniałem na początku Pandas to taki „kombajn”, w którym dostajemy mnóstwo funkcjonalności z pudełka.
Na początek prosty wykres naszych zaagregowanych danych o liczbie zestawów wypuszczanych przez Lego w poszczególnych latach.
In [38]:
df_year.plot()
Out[38]:
<AxesSubplot:xlabel='year'>
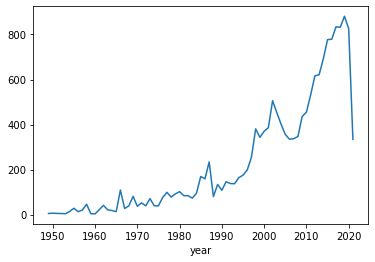
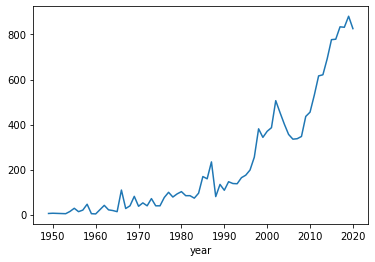
Wyświetlane dane możemy zawęzić, tak aby np. pominąć rok 2020 i 2021.
In [39]:
df_year.loc[:2020].plot()
Out[39]:
<AxesSubplot:xlabel='year'>
Wrócmy teraz do naszego data frame df zawierającego wczytane dane o zestawach Lego. Dla przypomnienia wyświetlmy próbkę danych w nim zawartych:
In [40]:
df.sample(5)
Out[40]:
| name | year | theme_id | num_parts | |
|---|---|---|---|---|
| set_num | ||||
| 8441-1 | Fork Lift Truck | 2003 | 7 | 69 |
| 4291-1 | Classic Build & Store Tub | 1999 | 470 | 770 |
| 5001132-1 | The Lord of the Rings Collection | 2012 | 566 | 0 |
| 5005526-1 | Blue Print Heritage Classic Backpack | 2019 | 501 | 0 |
| 80023-1 | Monkie Kid’s Team Dronecopter | 2021 | 693 | 0 |
Uruchomimy teraz metodę plot() DataFrame’a df:
In [41]:
df.plot()
Out[41]:
<AxesSubplot:xlabel='set_num'>
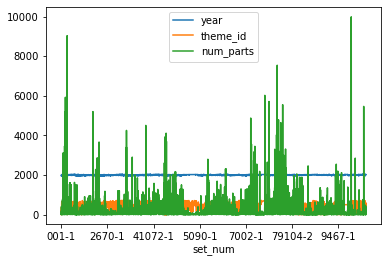
Porównując wykres z wyświetloną powyżej próbką danych DataFrame df widzimy, że w wyniku wywołania metody plot() utworzone zostały wykresy dla wszystkich jego kolumn zawierających dane numeryczne.
Możemy teraz zmodyfikować tą wizualizację w taki sposób, aby każdy z wykresów był prezentowany osobno. W tym celu uruchomimy metodę plot() z parametrem subplots=True.
In [42]:
df.plot(subplots=True)
Out[42]:
array([<AxesSubplot:xlabel='set_num'>, <AxesSubplot:xlabel='set_num'>,
<AxesSubplot:xlabel='set_num'>], dtype=object)
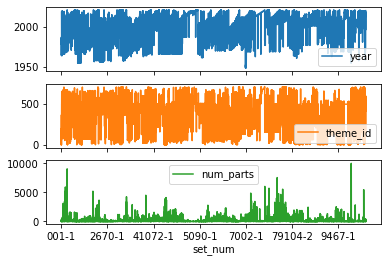
Pandas posiada o wiele więcej możliwości wizualizacji danych. W szczególności pozwala na tworzenie różnego rodzaju wykresów np. histogramu, boxplot, itp. Jest to jednak temat na co najmniej jeden dedykowany mu artykuł.
Zapisanie danych do pliku
Na koniec pokażę jak zapisać dane do pliku. Pandas pozwala na zapisywanie do różnego rodzaju plików, m.in. CSV, JSON, Excel. Poniższe polecenie pozwala na zapis danych do pliku Excela.
In [43]:
df_year.to_excel('wynik.xlsx')
W powyższym poleceniu jako parametr została określona jedynie nazwa pliku, co jest najprostszym wariantem. Podobnie jak w przypadku funkcji do czytania danych z pliku tak i w tym wypadku funkcja pozwala na szeroką parametryzację. Dokumentacja funkcji jest dostępna na stronie pandas.DataFrame.to_excel.
Podsumowanie
Celem niniejszego artykułu było pokazanie Ci jak używać podstawowych poleceń Pandas. Teraz czas na Ciebie. Pobierz notebook i wykonaj zawarte w nim zadania. Powodzenia!
Jeżeli ten artykuł był dla Ciebie wartościowy podziel się nim proszę w swoich social mediach.